大家午安~今天要跟大家介紹這個系列的最後兩種監督是機器學習模型-決策樹(Decision Tree)跟隨機森林(Random Forest)。不知道大家還記不記得小學考試的時候,自己最喜歡考卷上什麼類型的題目?我知道這個問題很詭異,幾乎不會有人真心喜歡考試,但在考試的時候總是會有比較喜歡遇到的題型跟比較不喜歡遇到的題型吧。以我來說,最喜歡的題型非「是非題」莫屬了。跟選擇題比起來沒那麼多選項,跟簡答題或填空題比起來又多了選擇,應該沒有比是非題對國小的我來說更讓我樂見的題目了。而今天要介紹的決策樹跟隨機森林就是用是非題來完成分類任務的模型。
上一季看的一部日劇裡面,剛好有適合用來解釋的情境,這邊就用它來舉例吧。在《騎上獨角獸》裡面,女主角的新創公司因為人力不足開始招募新員工。她提出了自己希望新員工要有的三個條件「具有獨立作業能力」、「對新事物有敏感度」,以及「率直」,但隨著面試的進行,他們一直找不到能完全符合這三個條件的應徵者也因而感到擔心。這種事在現實生活中應該也是一樣的,所謂「想像很豐滿,現實很骨感」,雖然我們大老闆心中應該都有完美員工應該要有的樣子,但能滿足所有條件的人是絕對少數,但總不能讓公司運作停擺到那個最合適的人選出現吧。這種時候我們需要的是決策樹(Decision Tree)的幫忙。決策樹在做的事情就是不斷地利用是非題將資料分成「是」跟「非」兩類,一直到可以把完全分出任務目標的兩類資料為止。在剛剛例子的情境底下就是我們蒐集公司現有員工的表現跟特徵之後,把他們區分成表現好的員工跟表現比較沒那麼好的員工兩類,接著讓決策樹根據這些資料去找出最能分出好員工跟壞員工的路。假設公司現在有100個員工,剛好就是好壞各半,然後根據這些員工的條件,假設我們問第一個問題的選項有兩個,「是否具有獨立作業能力?」跟「是否對新事物有敏感度?」,我們可以根據分群情況畫出下圖:
畫出這兩條路之後,決策樹決定哪條路比較好的標準就是哪條路可以得到比較多訊息增益(Information Gain),也就是哪條路能讓我們得到比較大的資訊量。提到資訊量,大家應該想到昨天介紹的資訊熵(Shannon Entropy)了吧?沒錯我們就是要運用entropy來計算每條路的訊息增益(雖然也可以用Gini不純度,但我們這邊就先以已經介紹過的Shannon Entropy為主)。為了幫大家喚醒記憶,這邊附上entropy的公式: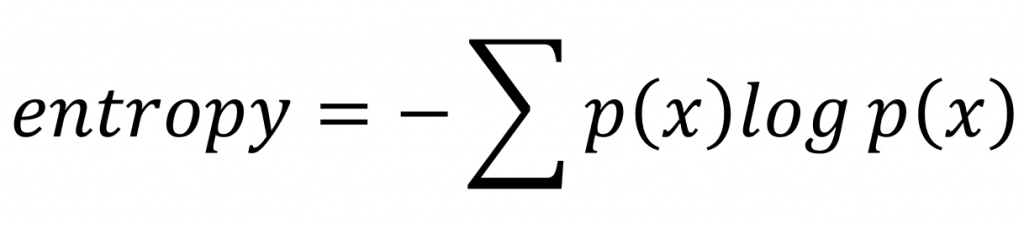
那我們就以2為底數來實際計算看看這兩條路的誰比較好吧~首先從初始資訊量開始: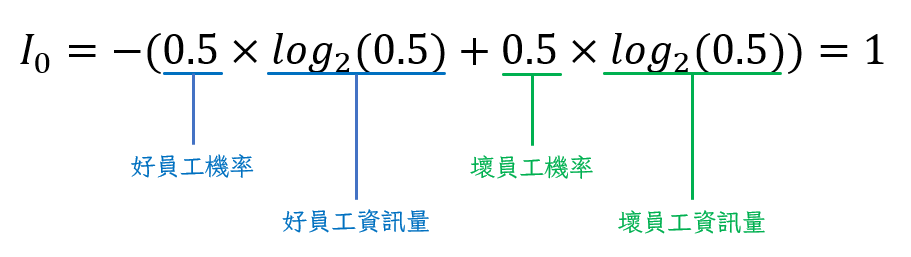
接下來是左邊的平均資訊量: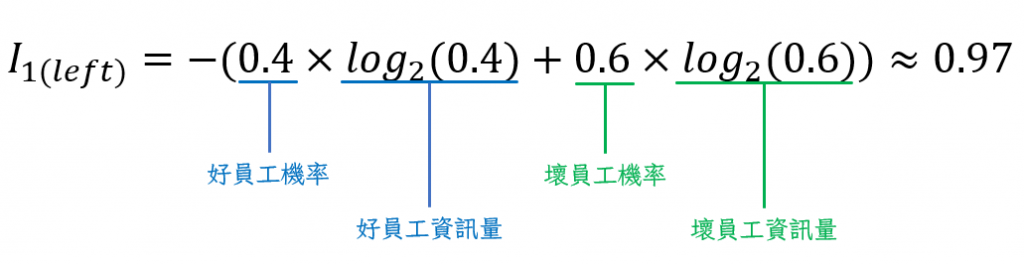
然後是右邊: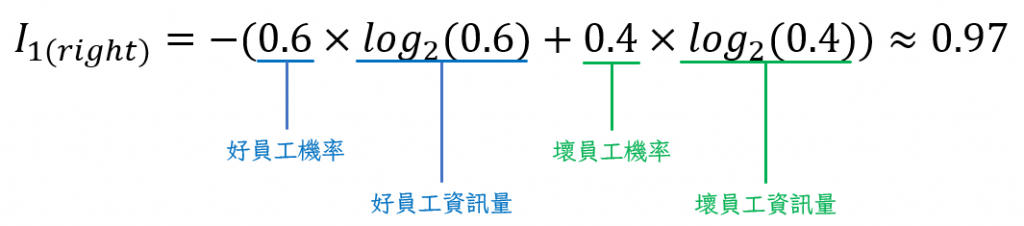
有了這些數字之後我們就可以用初始資訊量減掉左右兩邊分別的平均資訊量來計算這條路的訊息增益了: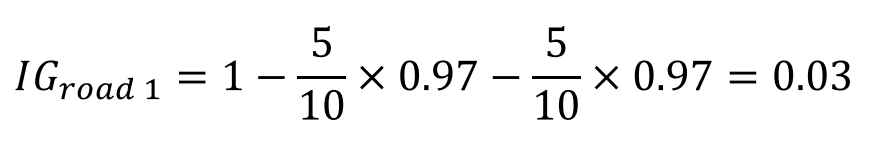
接著再對第二條路做一樣的事: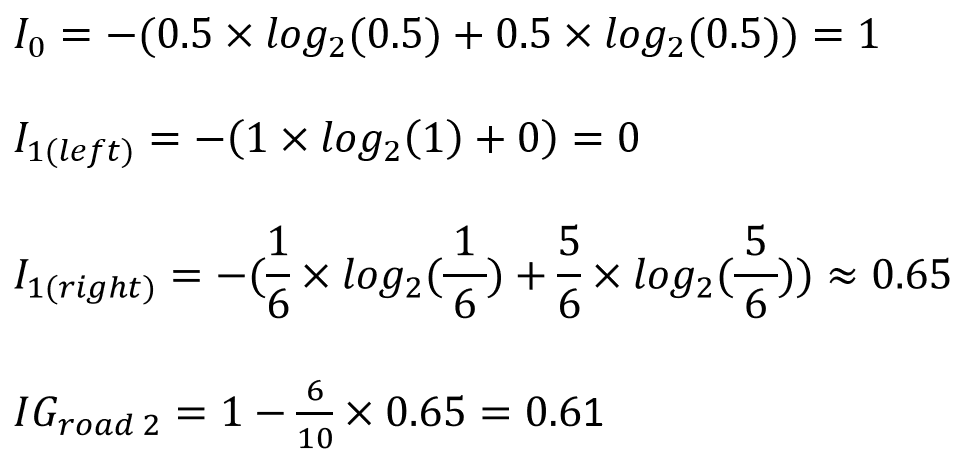
比較一下就可以發現第二條路的訊息增益比第一條路多,所以決策樹在做選擇的時候就會以第二條路為主繼續往下延伸其他是非題,一直到它把所有資料都分完群為止。完成之後,新丟進來的資料就會照著這條路被分類。
決策樹跟我們前面介紹過的其他模型比起來,最大的優點就在於它的解釋力很高。因為我們可以知道他種出來的樹長什麼樣子,所以就可以知道它的決策過程到底是什麼,而這是其他模型沒有辦法做到的東西。除此之外,它對缺失質比較沒有那麼敏感,而且計算量相較於SVM或Logistic Regression都還要小,比較節省時間。最棒的是它可以不只幫資料分兩類,如果我們的目標是把資料分成三個類別也完全ok。但它的缺點就在於比較容易發生過度擬合的問題而且比較不注重資料之間的相關性。還記得我們在介紹Logistic Regression的時候提到分類就是在平面上找一條可以把資料分成兩群的直線嗎?因為決策樹做的事情是一直用是非題對資料做二分法,所以如果想像成在平面上面畫線的話,它話出來的就不會是直線而是配合資料分布的,歪七扭八的線。因為這樣做的關係,它有可能太讓線貼近訓練資料。也就是說這條分群的線是在配合樣本的特色,而不是大群體的特色,所以當樣本不夠具有代表性,新資料進來的時候可能就會很容易被分錯地方。為了解決這個問題,就有了隨機森林(Random Forest)的誕生。
樹跟森林之間的關係是什麼大家應該都很清楚吧XDD 所以隨機森林就是很多棵決策樹形成的模型。這個時候問題來了!data set只有一個,計算最佳路徑的方法也只有一種,要怎麼生出很多棵不一樣的樹呢?重點就在這個「隨機」上面。當我們使用隨機森林模型的時候,每一棵樹都是隨機從訓練集裡面取出一部份資料種出來的。以上面的例子來說,就是我種第一棵樹的時候只取前80筆資料來用,種第二棵樹的時候只取後80筆資料來用,種第三棵的時候又把資料洗牌再隨機取80筆出來用,然後一直這樣類推下去。樹種到一定數量之後,就形成了隨機森林(Random Forest)。隨機森林做決定的方法就是把要分類的資料丟給每一棵樹,以多數決的方式決定分類,如果比較多棵樹分出來覺得這個人的特質比較可能是好員工的話,那就把他分類到好員工的類別裡面。因為這樣做不會用到全部的資料,也不會完全依賴一種資料分佈,每一棵樹會用到的特徵數量跟特徵種類,甚至是樹枝分幾岔都不一樣。因此就能夠避免過度擬合的情況發生,通常也能獲得比只種一棵決策樹好的結果。
以上就是針對決策樹跟隨機森林的介紹,下一篇會示範怎麼在python上面實際訓練這兩種模型,也會教大家怎麼把樹視覺化之後詳細了解模型的決策過程。如果有什麼問題都歡迎在下面留言反映,明天見!
[資料分析&機器學習] 第3.5講 : 決策樹(Decision Tree)以及隨機森林(Random Forest)介紹

